
Multi-Version Controlled Lock Violations for Snapshot Isolation
-
Table Of Contents
UNDONE: add back tags/series before publication
Introduction
In the world of concurrency control there are two approaches: pessimistic and optimistic concurrency control. Optimistic concurrency control assumes there are no conflicts and performs validation at the end of the transaction. While pessimistic concurrency control assumes there will be conflicts and detects those conflicts at the time of occurrence.
A benefit of detecting conflicts at the time of occurrence is transactions have flexibility in choosing what to do. The two well known options are waiting and aborting. There is also a third less discussed option, continuing execution. The transaction can speculate that the conflicting transaction will succeed and proceed as if it was committed.
The general approach to implementing pessimistic concurrency control is through locks. If one is unable to acquire the requested lock then there is a conflict. If the lock is granted, there are no conflicts and there will be no future conflicts. In the world of pessimistic concurrency control and speculative execution, there is the established approach of early lock release which I will discuss. And the more recent idea of controlled lock violations. I propose how one might extend traditional multi-version pessimistic snapshot isolation to support controlled lock violations.
Multi-Version Two-Phase Locking Snapshot Isolation
This section is a recap of well established ideas for implementing snapshot isolation with with pessimistic multi-version concurrency control. For the purposes of this post, multi-versioning is implemented as a version list of values that constitute a row. Additionally, it is assumed there is some sort of deadlock prevention/detection component (e.g. locks implemented as wait-die/wound-wait).
Combining multi-versioning with pessimistic concurrency control is very
effective for snapshot isolation. Read transactions do not block read-write
transactions. Reads work simply by doing a read of the latest value with
CommitTs <= StartTs. No concurrency control is needed. Only read-write
transactions need concurrency control.1
For snapshot isolation, we need to detect and prevent write-write
conflicts. Write-write conflicts are when another transaction, Txn B, writes
to the same row as Txn A, such that StartTs_A < CommitTs_B < CommitTs_A. In
plain english, Txn B inserted a row that was not visible to Txn A, so when
Txn A tries to write to the row it will have a write-write conflict. In order
to implement this with pessimistic concurrency control, we only need exclusive
locks. Once Txn A acquires an exclusive lock of the row, it is guaranteed that
no other transaction will commit a value with a commit timestamp less than Txn A.
A read-write transaction will perform their reads as of the transaction's start
timestamp. As with read transactions, visibility is based on CommitTs <= StartTs. Writes are performed as of the transaction's commit timestamp. There
is a detection phase and then a prevention phase for write-write
conflicts. First, the transaction determines if any of its writes conflict with
already committed writes. It asks, is there a committed value with CommitTs > StartTs?
In Figure 1, the Txn B encountered a value with CommitTs > StartTs so it
fails with a write-write conflict.
Now, lets look at the happy case where Txn A sees no write-write conflicts. It
acquires the row lock and inserts its uncommitted value into the version
list. Because it does not have a CommitTs, no reads or read-write transactions
have visibility of the uncommitted data (except for Txn A itself).
Then Txn B comes and wants to perform a write. It can't because Txn A owns
the lock, so it waits. It is not a write-write conflict because the value is
still uncommitted.
When Txn A commits, all of the waiters now have a write-write conflict so they
abort. CommitTs > StartTs for all waiters.
If Txn A aborted instead, the first waiter, Txn B, will now own the row lock
and can now insert its value into the version list and continue making progress.
Using PCC with multi-versioning eliminates the need for transaction private buffers for writes. Uncommitted values are able to be written in-place on the versioned list.
Arvola Chan, Stephen Fox, Wen-Te K. Lin, Anil Nori, and Daniel R. Ries. 1982. The implementation of an integrated concurrency control and recovery scheme. In Proceedings of the 1982 ACM SIGMOD international conference on Management of data (SIGMOD '82). Association for Computing Machinery, New York, NY, USA, 184–191. https://doi.org/10.1145/582353.582386
Strict Two-Phase Locking
To prevent dirty reads and cascading aborts with a simple implementation, strict two-phase locking can be used. Locks are acquired throughout the transaction, the growing phase. Locks are only released after the transaction is durable. The next section goes into the implications of releasing locks before the transaction is durable.
Early Lock Release
As one can surmise, it is beneficial to hold these locks for the shortest time period possible. The longer a lock is held, the longer conflicting transactions are blocked reducing concurrency. At the cost of more complexity, we can optimize how we hold locks after the growing phase to enable higher concurrency without dirty reads. There can be cascading aborts, albeit unlikely.
Because there is still a growing phase, the earliest we can release and still stay consistent with 2PL is after the commit request, no more locks will be acquired. This means locks can be released during the hardening stage. The hardening stage can be the dominant part of a transaction in OLTP workloads so enabling transaction progress during it can greatly increase performance during conflicts.
In figure 6 below, the blue line is the duration of a single node transaction. In strict 2PL the locks are held for the entire duration. With early lock release we only hold it for the green line as described above.

Releasing locks early can result in cascading aborts. However, in single node transactions we are doing the early lock release during the hardening stage. Generally, the only way a transaction aborts in this stage is if the database crashes. Therefore, cascading aborts do not matter. Waiting is strictly worse than speculatively proceeding, because if the database crashes the waiters would also abort.
A traditional early lock release implementation releases locks after determining its commit LSN. Assuming LSNs are strictly increasing, this creates a barrier. All transactions, acquiring the lock after the release will have a later commit LSN. Thus it satisfies the following:
- B can only commit after A commits.
However, this does not hold for read-only read-write transactions that do not
commit anything and thus do not acquire a commit LSN. Imagine Txn A releasing
its locks, Txn B returns those rows, and then the database crashes before Txn A is durable. That is a dirty read. This is what MySQL InnoDB implemented for
early lock release. They released locks before the fsync. Therefore they
cautioned about dirty reads: B can return some of A's data, and then there is a
crash before A commits.2 However, InnoDB reverted early lock release because
even with that known limitation, it did not work with their crash recovery
protocol.3
Therefore we need a new rule:
- B can operate on A's data inside the DBMS, but it must not return any of A's data to the client until A commits.
This is the rule that prevents dirty reads. This check can be implemented as a tag in the lock that stores the commit LSN of the latest release. In a read-write transaction that only performed reads, it will wait for the commit LSN to become durable.3
However, the high watermark is not efficient if the log supports out of order
commits. Imagine the following scenario. Txn B violated one of Txn A's
locks. Txn A is committed, but earlier in the log is a large Txn Z that is
still committed. Txn B can't commit because it needs to wait for the high
water mark to reach Txn A.
Txn Z (slow, committing) | Txn A (committed) | Txn B (waiting for HWM)
With a high watermark implementation, it may be faster for Txn A to not allow
the lock violation so Txn B could immediately acquire the lock and commit. For
correctness, this also assumes the out of order log will crash if one of the
commits fails. Otherwise high watermark does not mean all transactions below are
committed.
Additionally, this simple implementation does not support efficient two-phase commits. In two-phase commit there is the prepare phase and then the commit phase. Using high watermark only allows violations during the hardening of the commit phase. We are holding the much longer than necessary (the green line instead of red line).
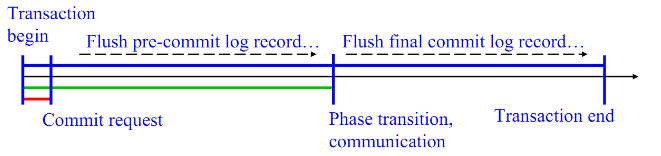
Therefore, we want a third rule to handle 2PC.
- B must abort if A aborts.
We are assuming here that 2PC aborts are rare because they can cause cascading aborts on failure. Unlike in the single node transaction, where waiters would also have been aborted (because of crash), waiters on the 2PC abort would still make progress. In the happy case though of 2PC succeeding, a 2PC transaction holds locks for the same amount of time as a 1PC transaction. There is still the overhead of a longer time to commit, but conflicting transactions are able to make progress in parallel.
If 2PC aborts have periods of high occurrence, the DBMS could dynamically switch from early lock release during the prepare phase to early lock release during the commit hardening phase, the green line. This would reduce concurrency but eliminate cascading aborts due to 2PC aborts.
Kimura, H., Graefe, G., & Kuno, H.A. (2012). Efficient Locking Techniques for Databases on Modern Hardware. ADMS@VLDB.
Controlled Lock Violation
Controlled lock violation is a slight reframing of early lock release. Instead of releasing the lock, the lock is still held and instead allows violations. One of the key benefits of controlled lock violation there is full visibility into the types of locks being violated. The paper focuses on the benefits this information has when using different lock types, hierarchical locking, and intention locks. There is a heavy focus on B-trees, and the paper's implementation is a boolean allow violation flag on a non-versioned B-tree.5
For our purposes, we are exploring how one can use the controlled lock violation ideas in the narrow context of multi-versioning and snapshot isolation. The benefits of having lock type information are unused because we only have a single lock type, exclusive locks.
An interesting observation is multi-versioned snapshot isolation as I talk about in this post does not really have the ability to do early lock release in the first place. The locks are embedded in the version list (through uncommitted values) and there is only a single type of lock, so it is impossible to "release" if a write is performed. The version list keeps the lock history.
Goetz Graefe, Mark Lillibridge, Harumi Kuno, Joseph Tucek, and Alistair Veitch. 2013. Controlled lock violation. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data (SIGMOD '13). Association for Computing Machinery, New York, NY, USA, 85–96. https://doi.org/10.1145/2463676.2465325
Multi-Version Lock Violations
To support controlled lock violations, our version list needs to support the following:
- Multiple uncommitted values that are dependent on each other.
- Timestamps to determine uncommitted value visibility.
To do this, our versioned values include a new field, ViolationTs. This is the
timestamp at which the locked uncommitted value allows violations. Violations
are allowed after the execution phase when the commit request is sent, which
keeps 2PL intact.
Read-only transactions are unchanged from the original design. They still determine
visibility using CommitTs: the latest value with CommitTs <= StartTs. This
is what ensures read-only transactions do not read uncommitted data and incur
commit dependencies.
Read-write transactions use ViolationTs for visibility: the latest value with
ViolationTs <= StartTs. Write-write conflicts are now defined using StartTs_A < ViolationTs_B < ViolationTs_A. This is the reduced time period of potential
write-write conflicts that we want. It works because when ViolationTs_B <= StartTs_A, A has visibility of B. Using ViolationTs instead of CommitTs
means B is possibly uncommitted, which is what the commit dependencies
track. Locks guarantee there is only a single possible future that is being
speculated and thus is visible.
Write Locking
Lets run through some scenarios to see how writes work in practice. The initial
state, seen in figure 8, has two committed values, and an uncommitted chain with
three values. As stated above, each versioned value has a ViolationTs and a
CommitTs (invalid values if not committed/allowing violations yet). Txn A
currently owns the exclusive lock on V2 (it was the transaction that inserted
V3). Txn H StartTs < V3 ViolationTs and Txn J StartTs < V3 ViolationTs so
they can only read V2. Therefore, they wait on V2 to be released
instead. V5 which owns Txn C has not been released yet.
Figure 9 shows the outcome of Txn A committing. Similar to strict 2PL snapshot
isolation, all the waiters abort with a write-write conflict. But, because we
speculatively made progress on the future based on Txn A, we are able to
continue with the uncommitted list. That is the key component of controlled lock
violations. Additionally, V5 started allowing violations.
Next up GC was performed removing some of the lower committed versions to make
the graphic easier for the reader. You can see that Txn B committed V4. Txn D (StartTs = 7) acquired the lock on V5 to insert V6. Notice that the read
timestamp is less than V4 CommitTs=9. This is why using ViolationTs instead
of CommitTs for visibility choices is important. The commit timestamp is
greater than the timestamps in the uncommitted chain. But our read-write
transactions need to have visibility into the uncommitted chain.
Finally a demonstration of a cascading abort. Txn C aborts which also causes
Txn D to abort. Because Txn K was waiting on V4 which Txn C originally
owned, it was able to acquire the exclusive lock and insert its own V5.
As you may have noticed, we kept the property that the uncommitted workspace is still the final version list. Writes do not need to operate on a private transaction buffer as there is only one potential future at a time. The single potential future is a key aspect of our speculative execution. There is only one potential future so transactions are able to easily perform snapshot reads of that potential future.
Waiter Behavior
The premise of lock violations is that it is extremely rare for transactions to abort once violations are allowed. Thus, waiters might as well produce the write-write conflict at violation time instead of commit time. By producing the write-write conflict as early as possible, it will force the transaction/user to retry faster. The retry will obtain a later read timestamp and will have access to the uncommitted version to make progress. Note that this approach is not illustrated in the scenarios above (write-write conflicts were detected at commit time).
Violation Atomicity
For correctness, allowing violations does not need to be performed for all writes at the same time. This is because a transaction will end up waiting for the outcome if the lock does not allow violations. However in practice allowing violations should be performed atomically. Take the scenario in figure 12 that uses multiple violation timestamps.
If Txn A commits, Txn B will abort because it is a waiter on Txn A in
Version List A. If Txn A aborts, Txn B will abort because it is dependent
on Txn A in Version List B. It is a guaranteed write-write conflict. If the
violation timestamp was set atomically for all writers this would be avoided.
Visibility of violations does need to be atomic though, just as
commits. Otherwise Txn B would be a waiter on Txn A's V2 even though the
ViolationTs <= StartTs.
Violation Timestamps
You may have noticed that violation timestamps do not interact with commit timestamps. Transactions that read using violation timestamps do not care about commit timestamps, and vis versa. Therefore, to reduce contention on the timestamp generator, the clocks can be separated. One clock for violations and another for commits. Read-write transactions get their read timestamp from the violation clock. Read transactions get their read timestamp from the commit clock. With this separation, commits and violations don't contend when incrementing.
Commit Dependencies
A handy benefit of the version list is commit dependencies are embedded in it. Transactions do not need to keep track of write dependents as during lock release they will visible in the version list.
However, the write set is not necessarily the same as the read set of a transaction. We also need to track commit dependencies for read rows. This is because we may be reading uncommitted data. So the transaction must wait for all commit dependencies to resolve before making its own commit decision.
We can implement this using the approach from High-Performance Concurrency Control Mechanisms for Main-Memory Databases.6
Each transaction, T, will have three new fields:
ReadCommitDepSet: A set of all the read transaction ids that depend onT.CommitDepCounter: A counter of all (read + write) transactions thatTdepends on.AbortNow: A boolean flag that other transactions can set to tellTto abort.
When T acquires an exclusive lock through controlled lock violation, it
increments its own CommitDepCounter. When T performs a controlled lock
violation for a read on another transaction, it increments its own
CommitDepCounter, and adds itself to the other transaction's
ReadCommitDepSet. It only does this for the value that is actually read (it
may have iterated through X uncommitted values before it).
During a commit/abort, T will iterate through its ReadCommitDepSet and
decrement the transaction's CommitDepCounter. During lock release, it will
also decrement the next value in the version's list CommitDepCounter. If it
was an abort, it additionally will set the AbortNow flag on all the
transactions.
In the following scenario, Txn A has not performed any lock violations so
CommitDepCounter = 0. Txn B violated the lock and read the V2 from Txn B,
so it added itself to the ReadCommitDepSet and incremented its own
CommitDepCounter.
If the database does not support two-phase commit and does not use an out of
order log, it can be simpler to implement the read dependencies using high
watermark. There would still need to be the CommitDepCounter and AbortNow
for write dependencies unless those also participated in the use of high
watermarks.
Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. High-performance concurrency control mechanisms for main-memory databases. Proc. VLDB Endow. 5, 4 (December 2011), 298–309. https://doi.org/10.14778/2095686.2095689
Write Row Return
When returning rows from a single-statement write, e.g. using PostgreSQL's Returning7 or Microsoft SQL Server's Output8 clauses, the behavior depends on the guarantees you want to provide.
If the results are of committed writes only, the inserted rows should return after the commit is durable as expected. If the behavior is similar to MSSQL Server,
An UPDATE, INSERT, or DELETE statement that has an OUTPUT clause will return rows to the client even if the statement encounters errors and is rolled back. The result shouldn't be used if any error occurs when you run the statement.8
then it is possible to stream the results back immediately for single-statement transactions. This is because the rows will be guaranteed to be committed if the statement is successful, because implicit commit will resolve the commit dependencies.
For Update
For update queries need to acquire the exclusive lock without installing a new
value, an exclusive read lock. This means it needs to be a read-write query. My
understanding of the semantics of a for update is exclusive access for the
duration of the execution phase of the transaction. As long as the semantics are
not "until the transaction is durable", the transaction can release the lock
early. Unlike write queries, no new value is inserted so when the transaction
determines its violation timestamp, the transaction will perform a true early
lock release of its for update locks. No ViolationTs needed and no causing
of write-write conflicts.
Unlike write row return above, returning rows from a for update can incur commit dependencies that we need to resolve. Because there are no special semantics about returning rows to the client in a for update query, we need to prevent dirty reads. See the section below on preventing dirty reads for handling commit dependencies when returning rows to the client.
I have not put much thought into shared for update queries. They require a shared lock which changes concurrency control significantly.
Two Phase Commit
It is important that when resolving read-only sites in two-phase commit, that commit dependencies are resolved. The transaction may have read some uncommitted data from the read only site, and made decisions on it or inserted it into a different site. They are dirty reads. Therefore, the prepare on the read-only site must fail if any of the commit dependencies fail.
Multi-Statement
With multiple statements, even if the first query is a read, subsequent queries may write. Thus multi-statement transactions have to use read-write semantics for all queries, even read-only queries. This is because each transaction type has its own visibility logic. Switching between the two for read/write statements would mean the transaction is seeing two different snapshots.
Preventing Dirty Reads
This means read statements in a multi-statement may have commit dependencies from reading dirty rows. The DBMS can operate internally on these rows without waiting for known outcomes. However, commit dependencies must be resolved for rows returned to the client to prevent dirty reads. The transaction needs to wait for the uncommitted row to become a committed row.
The wait for resolution of commit dependencies should be lazily performed. Query execution is likely to read more rows than actually returned to the user. Some form of row tainting may be a solution here. The transaction could taint the row with a txn id if it is uncommitted so when at the final stage of returning the row, a check/wait can be performed. If the query engine passes through the versioned value, then it already has access to the transaction to check/wait on.
An illustration of this is in figure 14. The query engine is processing a query
associated with Txn B. It wants to return V2 to the client. But, V2 is
associated with Txn A which is not yet committed so the query must wait. The
query engine will block on Txn A until it is committed and its rows can be
forwarded to the client.
Of course if Txn A instead aborted, then Txn B would also abort.
A nice optimization is when returning rows that the transaction wrote, one does not need to wait for commit dependencies. This is because the client is expecting to receive uncommitted data. This also applies to the write row return statement, because the write statement is not expected to commit. The rows returned will always be uncommitted. So regardless of the guarantees single-statement write row return provides, in the multi-statement no waiting is necessary.
New Multi-Statement Types
There are two new types of multi statement transactions that can be useful with controlled lock violation.
Read only multi-statement transactions
Because read queries have higher overhead in read-write transactions due to
commit dependencies, having read-only multi-statement transactions would allow
for multiple read queries as of the same timestamp with zero overhead. They
would use the CommitTs visibility rule for all the queries which prevents
commit dependencies. As the name implies, attempting to do a write query in a
read-only multi statement would produce an error.
Dirty read multi-statement transactions
Sometimes a multi-statement transaction that does reads and writes does not care about dirty reads. Imagine a transaction that reads some rows, does some processing outside of the database on them (e.g. building a full-text index or an embedding), then inserts the processed data back into the database. The client does not care that the data may be uncommitted because the data is only being used in the context of the transaction. The transaction commit will fail if one of the commit dependencies aborted. It can be thought of as extending the internal DBMS' use of dirty reads to the user transaction. These types of transactions should be able to opt out of the wait for commit overhead.
Multi-Version Lock Lists
While the focus of this post was on a multi-version list which embeds the
locks, what if the locks were in a lock manager and not embedded? If you
generalized the preceding proposal, it can be seen as a multi-version lock
list with visibility determined by ViolationTs.
In figure 15 there is a list of locks with Txn A owning the first one in the
history. A transaction is able to violate if StartTs >= ViolationTs. Txn D
has not allowed violations yet, so Txn K must wait.
Similar to how we multi-version data, I am proposing we extend that to our locks. For this to work, lock visibility and data visibility are tied together. This generalized idea of multi-versioning locking is something I propose as food for thought. It is a very undeveloped idea and has a bunch of unanswered questions, but it seems like a possible approach to implementing controlled lock violations for other lock types, e.g. hierarchical locks.
Wrapping Up
In the preceding sections I gave a crash course on multi-version two-phase locking snapshot isolation, went into the background of early lock release and what is required for proper speculative execution, gave an overview of controlled lock violations, and then introduced how one might implement it for multi-version snapshot isolation.
I approached the topic from a very narrow point of view, by investigating exclusive locks. A real database might will have more lock types, secondary indexes, etc. Also, I only covered snapshot isolation. Serializable isolation is desirable which requires read locks and uses different visibility logic. How these would work with controlled lock violations and multi-versioning is a topic for another time.
And with that this post is finished. I hope you learned something or at least got some good pondering out of it. My DMs and social accounts are always open if you have your own thoughts on the topic!